Software Occlusion Culling
26/Oct 2008
When I started my gamedev adventure I wanted to be a rendering/3D programmer. This was where I felt most confident. Just like 90% of demoscene coders, I didn’t have much experience with AI, physics or gameplay, it wasn’t really needed for demos. Later it turned out that other areas are very interesting as well, I ended up doing them all at one point and nowadays I don’t really code much 3D stuff. I had brief period at CDPR when I was doing it professionally, but other than that I mostly deal with low-level system/gameplay stuff. I still try to follow latest trends/techniques, but I wouldn’t consider myself 3D programmer anymore, especially comparing to guys who do it every day. However, from time to time some idea may spark my interest strong enough to give it a try. This was the case with software occlusion culling.
I’ve first read about it in Johan Andersson’s (DICE Rendering Architect) presentation from Graphics Hardware 2008 - ‘The Intersection of Game Engines and GPUs - Current & Future’. Well, ‘first’ may be not the best term, it’s an old technique, I’ve been using something similar in my software 3D engine some 10 years ago (it came almost for free, as I’ve been maintaining sofware depth buffer anyway). Then first GPUs arrived and took care of a big chunk of rendering pipeline. Recently CPUs became powerful enough to give this technique a try again.
Basic idea is very simple, you render depth of potential occluders to special buffer, then test bounding volumes of objects against values in the depth buffer. Rendering of occluders has to be done in software. For the purpose of this experiments I created simple scene with some buildings aka cubes (with subdivision, random number of faces), ground and 40 skinned characters wandering around the ‘city’. Without any kind of occlusion culling, just VFC, in typical situation we have around 200k triangles to render. It’s not a terribly realistic scenario, but should be OK for our experiments.

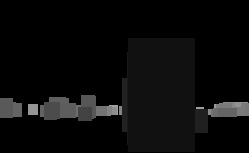
Transformation/clipping can be easily parallelized as well. I went easy way and even with display list access guarded with mutexes it still is fair bit quicker than doing this in a single thread.
Results of our occlusion culling in action can be observed at Figures 4 & 5.


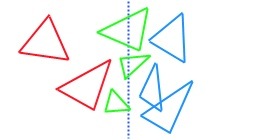
Now, before you rush to code it yourself - a word of caution. One problem that I noticed is when we consider very ‘long’ boxes tested against occlusion buffer with narrow gaps. See Figure 6:
Let’s wrap up. Advantages of software occlusion culling:
very small amount of artist work required. No manual occluder placing needed.
predictable/stable/small overhead. DICE simply limits their occluding geomtry to 10k triangles per frame. Determine your limit by yourself, measure the overhead and you won’t go over that (especially if you implement ‘big occluder’ test I described before).
easily parallelizable. You can either run whole process in different thread, or parallelize stages like I did here.
works in screen space/with model geometry. Most occlusion culling algorithms perform geometry tests on bounding volumes and thus are less exact (conservative, but still).
lends to high level optimizations nicely. I didn’t try it, but all the usual tricks that apply to hardware occlusion culling, should work here as well. One thing that I’d definitelly try if occlusion tests would prove costly is Jiri Bittner’s stuff.
[forgot about this one orignally] unlike HW occlusion culling (using queries) runs 100% at CPU, so no GPU<->CPU synchronization problems and it can parallelize nicely. Should work great on systems with relatively powerful CPUs and slower GPUs (…)
One disadvantage I can think of right now is the problem mentioned in previous paragraph. I guess there could be more when implemented in a full-blown game situation. It still is worth a try, though, mainly because it’s really simple. Whole system can be easily implemented in a day or two. If it works - great, spend some more days on optimizations and you’re set. I’d say it certainly looks easier than alternatives.
Finally, in a typical fashion of including totally unrelated links, interesting talk I found today: YouTube Scalability by Cuong Do. It doesn’t have anything to do with gamedev, but it’s good to widen your horizons from time to time. I dont know crap about the subject he’s talking about, but it still was pretty interesting. Crazy thing is, they maintained YouTube with like 10 people for a long time.
Old comments
ed 2008-10-26 20:25:37
Wouldn’t be better use software clipping in 2d ? Instead of rendering occluders to buffer, you would just project occluders into 2d space and make a list of 2d convex (or non-convex) polygons. Then you can clip-intersect objects with this list. This would solve fig. 6. Additionally since modern processors have good paralel computing capabilities but still struggle with memory bandwidth; having few more computations can be better than memory accesses (especially that you need to sample more points to avoid fig.6).
Arseny Kapoulkine 2008-10-26 20:29:30
Interesting, I wanted to implement it both for PC and for SPU but did not have the time to try. Perhaps I’ll find some after your post :)
What are the performance numbers?
admin 2008-10-27 07:12:15
ed: interesting idea, didnt think about it. You couldn’t clip/intersect in full 2D, though, as depth is important here as well. Getting the “shape” of occluder may not be trivial, also.
Arseny: I imagine it should work very nicely with SPU especially. About performance numbers, I didnt post them, because the scenario isnt terribly realistic – rendering is rather cheap (just skinning+texture+directional light) and on the other hand there are many occluders. Anyway, normally I render about 150-170k faces at 17ms per frame without occluding and 70-90k at 10ms with occlusion culling (that’s normal situation, nothing extreme, like standing in front of a huge cube etc). Tested on my crappy laptop (GF8600).
Arseny Kapoulkine 2008-11-02 18:44:29
I meant the occlusion performance actually - i.e. for some of that screenshots, how much time does it take to draw how many occluders in occlusion depth buffer and how much time does it take to qualify how many objects (OBBs?)
admin 2008-11-02 19:44:03
I rasterize about 1200 faces per frame in 0.8-1.2ms (boxes consists of random number of small polys, just to increase complexity and make it more realistic). Transformation seems to be a bottleneck and takes ~3.5-4.5ms. Occlusion test of AABBs - up to 1.5ms (I test 8 points). I expect it can be speeded up noticeably, I didnt spend that much time on optimizations.
realtimecollisiondetection.net - the blog » Catching up (part 2) 2009-06-08 08:52:05
[…] Sinilo wrote a good post on software occlusion culling. I know of several games (from different companies) that have used software-rasterized occlusion […]
convex graph 2010-03-29 01:46:20
[…] … the slope of my utility function strictly convex. Trust me ladies, with me there is no …Software occlusion culling | .mischief.mayhem.soap.Old occlusion culling method becoming cool again! … Instead of rendering occluders to buffer, you […]
ben 2010-04-24 00:14:49
Where can i find the source code to your ingenious solution?
Regards,
Ben
Fix your game DICE - Page 2 - Electronic Arts UK Community 2012-05-21 16:06:46
[…] GPU Gems - Chapter 29. Efficient Occlusion Culling Hierarchical-Z map based occlusion culling Software occlusion culling | .mischief.mayhem.soap. I could post what Kalm's thinks it is but it won't really matter. They don't consider it a bug or […]