EA STL released, updated benchmarks
22/Oct 2010
Big weekend news were EA releasing some of their codebase source, including parts of EASTL. Given that the original EASTL document has been the main inspiration for my RDE STL experiment, I was very interested in finally seeing the code itself. First impression - it’s still big. It is leaner than STL, but it is a big library. That’s quite understandable if you remember it’s not a local, one studio thing, it’s used by the whole organization. Thus, it includes features like optional exception support, that in other situation could be easily ignored. I was especially curious to test how their hash map implementation performed when compared to Google’s or RDESTL.
hash_map tests were done using Google’s sparsehash (v1.9), ran them on my old laptop (Core Duo 2.2GHz, first value) and desktop machine (8 core, i7@2.8GHz, second value). All benchmarks were run for three different types of objects - sizes of 4 bytes (5000000 iterations), 16 bytes (1250000 iterations) and 256 bytes (156250 iterations). Results presented in tables below (omitted sparse_hash_map (slowest by far) and std::map. See my previous post for test description):
| 4 byte objects | dense_hash_map | rde::hash_map | stdext::hash_map | eastl::hash_map |
| map_grow | 1273.8/365.9 ns | 699.0/205.9 ns | 2095.8/535.7 ns | 1815.9/402.3 ns |
| map_predict/grow | 535.6/169.4 ns | 461.5/151.3 ns | 2209.3/544.2 ns | 1833.8/421.3 ns |
| map_replace | 351.9/128. ns | 369.9/116.9 ns | 540.2/167.0 ns | 395.6/121.9 ns |
| map_replace2 | 377.0/130.4 ns | 322.3/94.2 ns | 513.5/158.3 ns | 354.1/118.8 ns |
| map_fetch | 370.9/125.8 ns | 309.3/98.4 ns | 514.3/155.0 ns | 412.9/103.7 ns |
| map_fetch_empty | 101.1/28.2 ns | 35.5/8.4 ns | 224.6/54.9 ns | 191.3/42.8 ns |
| map_remove | 495.2/158.8 ns | 370.4/121.4 ns | 2131.5/577.2 ns | 587.9/163.2 ns |
| map_toggle | 1050.9/238.9 ns | 479.5/121.6 ns | 3470.2/844.6 ns | 1193.9/264.5 ns |
| 16 byte objects | dense_hash_map | rde::hash_map | stdext::hash_map | eastl::hash_map |
| map_grow | 2760.6/685.5 ns | 1235.3/282.7 ns | 1964.5/1016.3 ns | 2057.8/522.9 ns |
| map_predict/grow | 934.5/258.5 ns | 715.4/210.7 ns | 1802.9/1026.8 ns | 2044.4/528.7 ns |
| map_replace | 693.0/199.8 ns | 569.9/172.0 ns | 774.8/178.5 ns | 651.9/214.8 ns |
| map_replace2 | 826.6/204.4 ns | 549.5/168.9 ns | 783.1/176.4 ns | 628.4/204.2 ns |
| map_fetch | 712.9/203.6 ns | 537.5/159.0 ns | 765.9/177.1 ns | 627.4/200.2 ns |
| map_fetch_empty | 152.3/40.5 ns | 87.7/23.7 ns | 169.5/91.6 ns | 369.7/78.8 ns |
| map_remove | 931.8/252.9 ns | 588.1/164.0 ns | 1708.3/1481.7 ns | 823.1/221.4 ns |
| map_toggle | 2220.7/509.0 ns | 903.3/215.5 ns | 1414.6/896.6 ns | 1785.7/371.3 ns |
| 256 byte objects | dense_hash_map | rde::hash_map | stdext::hash_map | eastl::hash_map |
| map_grow | 16839.8/3724.5 ns | 5786.5/1360.1 ns | 12130.4/3012.7 ns | 7629.7/1831.8 ns |
| map_predict/grow | 4675.8/1174.3 ns | 3845.0/934.9 ns | 12281.7/2969.9 ns | 7411.1/1852.1 ns |
| map_replace | 3893.9/999.0 ns | 3334.1/800.1 ns | 3307.8/789.5 ns | 3239.0/763.0 ns |
| map_replace2 | 4039.3/1018.4 ns | 3298.5/807.4 ns | 3222.9/815.0 ns | 3234.3/838.3 ns |
| map_fetch | 3941.6/978.8 ns | 3186.0/820.3 ns | 3173.7/797.6 ns | 3188.8/819.7 ns |
| map_fetch_empty | 233.6/66.3 ns | 158.3/46.1 ns | 3057.8/749.3 ns | 2954.8/720.3 ns |
| map_remove | 4457.8/1116.7 ns | 3301.5/785.4 ns | 9395.7/2347.9 ns | 3408.8/928.7 ns |
| map_toggle | 9773.2/2334.4 ns | 6438.6/1525.4 ns | 13127.5/2931.8 ns | 9738.0/2437.8 ns |

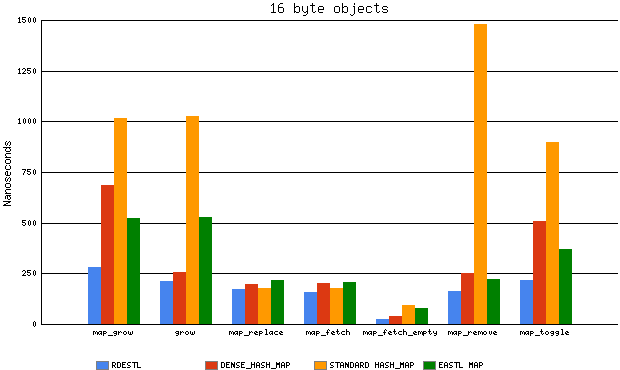
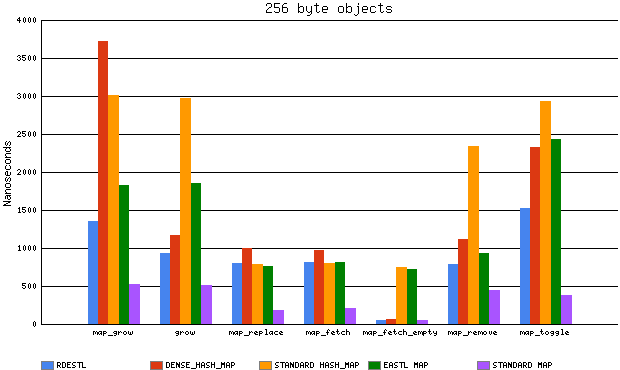
I ran also my own test, which included adding names of all files from c:\Windows\System32 to a (hash)map, performing some look-ups and then removing them. In general EASTL was quite close to RDESTL here (excluding construction), both quite clearly faster than standard implementation. std::map, rde::map & eastl::map were included in the test as well, and while they were slower than hash_maps, EASTL was clearly the fastest from those three (with RDE ‘fetch’ being the slowest, slower than MSVC implementation even, will have to take a look there). Typical results (in ms, laptop):
| Grow | Find | Remove | Total | |
| RDE hashmap | 191 | 133 | 105 | 429 |
| EASTL hashmap | 182 | 155 | 108 | 445 |
| STD hashmap | 222 | 185 | 240 | 647 |
| EASTL map | 253 | 584 | 278 | 1115 |
| RDE map | 252 | 709 | 338 | 1299 |
| STD map | 228 | 601 | 482 | 1311 |
In general, switching to EASTL should be a no brainer for any companies that are still using STL, if only for better memory management. If you have your own implementation, you probably want to run similar benchmarks yourself first, but I’d say it’s worth at least giving a try (not the whole package maybe, as I mentioned - it may be a little too big for everyone’s taste) . It’s clearly visible that it was written by someone, who actually cared about performance/memory management.
Appendix: all charts in this note were generated using Perl. I wrote a little script that parsed program output and generated images using built-in module. It was the first time I wrote something in Perl. Impressions? Boy, is it powerful when it comes to working with strings (shocker, I know). Whole parsing code is maybe 15 lines and I’m sure could be half of it, were it written by someone who actually knew what he was doing. Syntax is ugly, yes’ It’s good to be concise, but here it was pushed a little bit too far. I think I still prefer it to Tcl. Thing I absolutely hated was that statements need to end with a semicolon. For some reason when I code in a scripting language I immediately switch to sloppy, non semicolon mode. What’s more annoying - error messages are completely bogus in such case, I think I’ve seen at least 10 different ones. After a while I just learnt that if message didn’t make any sense - it’s a semicolon missing somewhere.
Old comments
Paul 2010-10-22 08:53:33
Which compiler and OS did you run theses tests with?
Have you also compared to tr1:unordered_map?
Ofek 2010-10-22 09:59:42
Maybe add STLPort to the benchmark?
Sebastian 2010-10-22 12:38:56
Thanks for posting these benchmarks. Like the previous poster I think it would be great if you could include a test case for unordered_map. I’m mostly interested in boost’s implementation.
http://www.boost.org/doc/libs/1_44_0/doc/html/unordered.html
snk_kid 2010-10-22 13:12:53
You should try do this with with (pre-)C++0x enabled library implementations that support features such as move semantics and again later once C++0x offically out and has better support with other compilers.
VC++2010 supports move semantics and in their STL implementation. tr1::unordered_map is std::unordered_map in C++0x, there should not be any significant difference between std::unordered_map and stdext::hash_map except for move semantics and slight interface differences.
admin 2010-10-22 23:23:57
Code was compiled with MSVC 2008.
Tests run under Windows Vista 32-bit (laptop) and Windows 7 64-bit (desktop).
I’ll try to add boost/STLPort over the weekend. Basically, it’s unmodified Google’s benchmark from their sparsehash library, so if anyone’s in hurry, it should be simple enough to give it a whirl.
snk_kid 2010-10-23 13:43:44
Ideally you should do this for a number of compilers, there will be differences. You should definately do this with VC++2010 because you should see a sigifnicant differences because of rvalue references and move semantics and a better optimizing compiler. Get the express edition it’s free.
admin 2010-10-23 14:03:23
I’ll give 2010 a try some day. Reason why I’m not particularly interested in testing move semantics right now is that it’s not widely support by console (X360/PS3) compilers anyway.
Steve 2010-10-25 06:53:29
xp 2010-10-25 18:32:58
for those wondering how unordered_map performs, check out this benchmark: http://attractivechaos.wordpress.com/2008/10/07/another-look-at-my-old-benchmark/
it’s a little dated but I think most results are still good today.
EASTL publicada como open source « martin b.r. 2010-11-12 10:57:27
[…] autor, Paul Pedriana, ha conseguido publicar una versi??n (m??s o menos el 60%) como open source. Aqui teneis un extenso analisis de sus […]
Adrian 2010-11-18 11:32:30
Would be interesting to see a comparison vs PS3/360.
I’d bet that they’ve paid more attention to keeping a smaller cache happy and the differences between best and worst are exaggerated further.
Adrian
admin 2010-11-19 03:19:44
X360 benchmarks can be found here: http://msinilo.pl/blog/?p=675 .
dk1rein 2010-11-22 10:35:11
Would be interesting to see a comparison vs PS3/360.
Hubert 2011-12-08 14:46:54
I did a comparison of std STL, RDE, ea STL on PC/win7, x360 and ps3: http://imageshack.us/f/545/wyniky.png/
Compiler was VS2010, all optimizations on
Can you comment on the results? Especially about vector.erase on x360
If you want I can share benchmark’s code
{kind=link}
admin 2011-12-08 15:37:58
Thanks for the test, looks interesting. What was the stored element type? I’d have to take a look at erase() myself, I might be doing something stupid there, I mostly use unordered version, so didn’t focus on it too much (it’s still surprising it’s so slow only on X360). If stored element is POD, specializing is_pod might help.
Hubert 2011-12-09 16:35:12
Thanks for answer :] All tests for vector, list and deque were made on uint32_t.
Today I tested it also on android 2.3 NEON (Xperia Play), and again - vector.erase in rde lasts 13843m, compared to ~8200 in stl and ea. I’m gonna test also how it behaves for bigger structs, and come back here.
admin 2012-09-05 03:12:00
Doh, forgot about this one. Seems like there was a bug that would cause unsigned values to be treated as types requiring copy constructor and nullify some of optimizations. It has been fixed, feel free to give a new version a try.