Clash of the Thread Pools
26/Aug 2010
Recently, I’ve been experimenting a little bit with different kinds of MT-safe containers. I wanted to compare a performance of various kinds of containers I’ve had lieing around. It turned out it’s more tricky than I expected, as under Windows, results vary wildly from one run to another. I’m not even speaking about container performance, just running same task can be many times slower (see this note for example). Include similar problems with managing the threads themselves (sometimes they wake up too late or not at all) and you should get the picture.
My test included the following types of thread pools:
- lock (critical section) based, vector-like container,
- multiple SPSC queues,
- lock-free MPMC queue (a’la Fober et al.),
- lock-free MPMC stack,
- bounded MPMC queue (by Dmitry Vyukov, presented here),
- double ended queue (a’la Herlihy et al.),
- straighforward SPMC queue (tuned for batch processing),
- just for kicks, I included TBB parallel_for as well
I actually had few more (another variant of DEQueue, with locks for slow path, one based on I/O completion ports), but those are the ones that made the cut.
My SPMC queue is very simple, single thread adds elements, then multiple threads can access them using interlocked increment (for pop index). In theory, it should be pretty quick however:
- elements cannot be consumed at the same time they’re produced,
- if you know how interlocked increment works under the hood, it’s really not that much more efficient then CAS.
Before starting with experiment, I had to make sure all those containers worked as expected. The best tool for verifying such assumptions (that I know of) is Relacy (by Dmitry, again). Lock-free code is too dangerous to take risks, I do not consider any code that doesn’t pass Relacy tests to be safe (hell, even passed tests don’t really guarantee anything).
Running Relacy stress tests allowed me to find a subtle bug in bounded double-ended queue presented in The Art of Multiprocessor Programming. I might be missing something (tried to contact the authors, but no luck), so let me present the simplest repro case I could find (I’d be thankful for any comments). Please refer to publicly available presentation for more details of original implementation (slides 124 & 130):
1public Runnable popTop() {
2 int[] stamp = new int[1];
3 int oldTop = top.get(stamp), newTop = oldTop + 1;
4 int oldStamp = stamp[0], newStamp = oldStamp + 1;
5 if (bottom <= oldTop)
6 return null;
7 Runnable r = tasks[oldTop];
8 if (top.CAS(oldTop, newTop, oldStamp, newStamp))
9 return r;
10 return null;
11}
12Runnable popBottom() {
13 if (bottom == 0) return null;
14 bottom--;
15 Runnable r = tasks[bottom];
16 int[] stamp = new int[1];
17 int oldTop = top.get(stamp), newTop = 0;
18 int oldStamp = stamp[0], newStamp = oldStamp + 1;
19 if (bottom > oldTop) return r;
20 if (bottom == oldTop) {
21 bottom = 0;
22 if (top.CAS(oldTop, newTop, oldStamp, newStamp))
23 return r;
24 }
25 top.set(newTop, newStamp); return null;
26}- two threads, shared queue. Thread 1 produces items and pushes them to the bottom of the queue, thread 2 steals them from the top.
- thread 1 pushes item A, bottom index = 1, top index = {0, 0} (index + control stamp),
- thread 2 pops item A from the top, bottom index = 1, top index = {1, 1},
- thread 1 pushes item B, bottom index = 2, top index = {1, 1},
- thread 2 enters PopTop, loads top {1, 1}, loads bottom (2),
- thread 1 enters PopBottom, loads bottom (2), decreases bottom (1),
- thread 2 increases top {2, 2}, bottom = 1 (2nd item popped, queue empty),
- thread 1 loads top {2, 2}, bottom (1) < top, no early exit,
- thread 1, bottom != top either, not setting bottom to zero, not trying to set top to zero with CAS,
- thread 1, top = {0, 3}, return NULL (last line),
- thread 1 enters PopBottom, loads bottom (1), decreases bottom to 0, loads top {0, 3},
- now bottom == top, new top set to {0, 4}, item at index 0 returned (third item from the queue that only had two!)
The way I fixed it was to move bottom=0 assignment outside of the if (bottom == oldTop) condition block, so that it’s zeroed always if queue is empty. Final version can be found in attached code.
For performance testing, I decided to use scenario that’s a little bit more realistic than trying to draw Mandelbrot fractals, namely - raycasting. Basically, the task was to trace 10000 rays against the model of Stanford Bunny (69451 tris). Single task batch consisted of 20 rays (trial & error). Differences in task durations were really significant, which meant I needed good load balancing (one of the reasons why SPSC scheme struggled).
Now, keep in mind it’s still environment focused mainly on pure data processing. It only measures how long does it take to complete a task using all worker threads + main thread (doing nothing, but helping). In games it’s more often that main thread creates work then goes on and deals with its own stuff and when it’s done it may ask about the status and maybe help if there’s anything left (as opposed to blocking on task immediately, parallel_for style). It also means that in many cases performance of your task system isn’t really that crucial, as long as you’re done before main thread asks for results - you’re fine. In my test app, there’s a possibility of ‘simulating’ main thread being actually busy with own stuff, feel free to give it a go, it should much closer to real life scenarios.
As I mentioned before, it’s hard to draw a definite conclusions, as results vary from run to run, however after many tests, typical ordering (fastest->slowest) was (8 core machine, i7@2.8GHz, 7 worker threads, average of 5000 iterations):
- MPMC queue: 0.292600 ms
- MPMC stack: 0.299673 ms
- Bounded MPMC queue: 0.319365 ms
- SPMC: 0.366890 ms
- DEQueue: 0.373112 ms
- Locks: 0.380752 ms
- TBB: 0.456420 mss
- SPSC: 0.523832 ms
- Single threaded: 1.455401 ms
Additionally, I measured the overhead of single pop operation for various container type and how it scales with increasing number of threads fighting for access.
| Number of worker threads | ||||
|---|---|---|---|---|
| 1 | 3 | 5 | 7 | |
| Locks | 198 | 210 | 314 | 404 |
| SPSC | 24 | 26 | 28 | 30 |
| MPMC stack | 37 | 47 | 45 | 46 |
| MPMC queue | 45 | 49 | 54 | 57 |
| Bounded MPMC q | 80 | 85 | 94 | 111 |
| DEQueue | 100 | 123 | 123 | 120 |
| DEQueue steal | 132 | 130 | 130 | 139 |
| SPMC | 50 | 47 | 55 | 52 |
Table 1: Summary of pop/steal overhead (in CPU cycles)
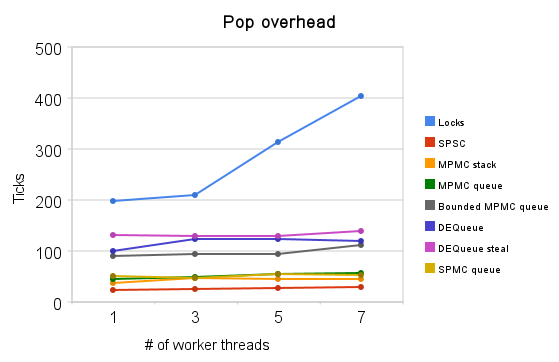
Image 1: Pop overhead chart
As you can see, most algorithms actually scale quite nicely (I’d love to try it with larger number of cores one day, was thinking of using that Intel’s initiative but never got around to actually do it).
In order to get a better picture of what’s exactly going under the hood I extended a little bit my ThreadProfiler (so that it records custom threadpool events). Below you can find comparions of two runs of MPMC queue (notice it’s the same scale!). As you can see, not only was one worker thread inactive for the whole time, also same tasks were simply taking more time (blue bars represent tasks, ‘pink’ is where main thread produces jobs, running times were ~0.22ms vs ~0.75ms).
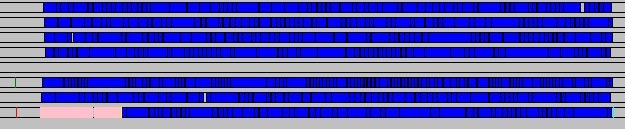 Image 2: MPMC queue, ‘slow’ (~0.75ms) run
Image 2: MPMC queue, ‘slow’ (~0.75ms) run
 Image 3: MPMC queue, ‘fast’ (~0.22ms) run
Image 3: MPMC queue, ‘fast’ (~0.22ms) run
Both problems are a little bit platform specific, on PS3 for example we could care less about putting SPUs to sleep, also on both consoles task durations should be more consistent between runs. Not sure if there’s much you can do under Windows, I’ll look into it some more.
Now, judging just by pop overhead, it looks like SPSC queue should be a clear winner. Sadly, it suffers the most from the problem of poor load balancing. Admittedly, I worked very briefly on that aspect, my first solution was to have main thread distribute tasks based on how busy workers are. Obviously, this means it has to block, otherwise work doesn’t progress. If we want main thread to continue with other jobs, we’d have to create a new ‘distributor thread’ (more context switches, in my tests does more harm than good). One idea that I’m toying about and will definitelly want to give a try is work requesting a’la this post by Dmitryi Vjukov (I think you may begin to see a pattern here). My gut feeling is that this scheme can really shine with enough effort put into working around balancing problems. It’s the most simple, it doesn’t suffer from contention, but extra work needs to be done in distributing area.
That’s probably true for other containers as well. As you can see the differences between them are very little, it’s probably better to focus on designing the whole ‘flow’ of the system rather than trying to squeeze cycles at the very low level (unless you do it for education/fun, like yours truly). I was quite disappointed by DEQueue performance, to be honest, it’s supposed to shine here. Sadly, it seems that ‘fast path’ is not that fast after all. It also gave me most problems, apart from the one mentioned before, I had some other, implementation related one (I didn’t load all 64-bits of m_top in one instruction, so part of it was not up-to-date, that’s probably one of the reasons why PopBottom is not as fast as it could be).
MPMC queue usually was doing a little bit better than MPMC stack, even though pop operation takes more time. That’s most likely because of better cache usage (FIFO vs LIFO… now that I think of it maybe I can test version where I add tasks in opposite order).
Future work: mostly working on scheduling/distributing, with focus on SPSC scheme. Source code for described experiment can be downloaded here. Doesn’t include Relacy, you can download it independently and put in ‘external’ directory. If you want to run context bound Relacy tests, make sure you’ve lots of time/run them with 2-3 threads (otherwise it can take ages). Stanford bunny model can be downloaded here (bunny.tar.gz includes .PLY file). Application builds kd-tree when it’s run for the first time. Then it’s saved, using the latest version of my reflection system (loving it! Here’s code for loading the tree structure:
Impl* impl = LoadObject<Impl>(f, typeRegistry, Impl::VERSION);