Intel Thread Profiler
12/Jun 2008
Few days ago I decided to have closer look at my multi-threaded experiments, mainly to check if there really is any kind of difference between code based on locks and lock-free version. Downloaded evaluation version of Intel Thread Profiler and gave it a try. Especially for this experiment, I modified scenario a little bit. Mandelbrot is not the best test as tasks take relatively long time (with selected number of iterations one ‘frame’ would take over 2 seconds). I replaced it with animating 2000 meshes (transforming all vertices with CPU), duration of single task depended on number of vertices, but program was running about 30 frames per second.
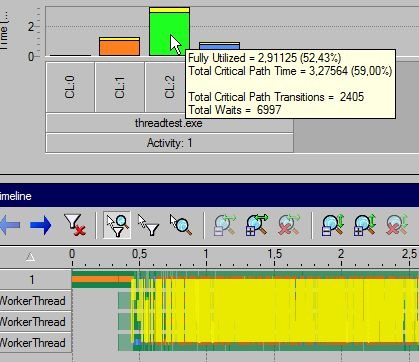
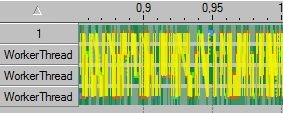
Let’s start with first, basic version with critical section. Every access to task queue is guarded with locks. Worker threads wait on semaphore and they’re activated as soon as there’s some job for them. Rather straightforward solution, really. Hopefully I didnt do anything stupid, locks are held for shortest duration possible (released before executing task etc). Every frame we add our animation tasks, then main thread fakes some job it has to do and finally wait for worker threads to finish animating. Let’s run it under ITP, result shown at Figure 1.
Another try - naive lock-free implementation. Lock-free FIFO task queue, semaphores for communication between main/worker threads. Result:
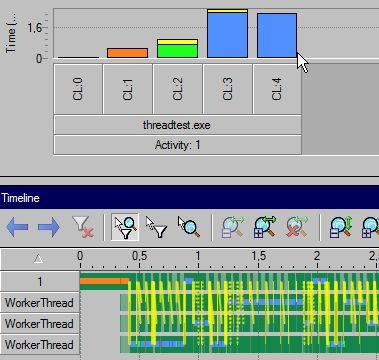
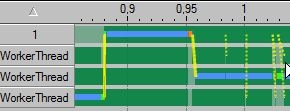

Of course, those pictures are pretty, but we shouldnt forget that our goal is to speed-up the application, not to minimize contention (it may be a way to achive this goal of course). You could easily have zero yellow bars, simply by letting worker threads spin until there’s work for them, it just wouldnt make much sense’
Anyway, what’s “real” difference between all those versions? Not that big, honestly, fractions of one frame (usually it’s ~29.3 (version 1) fps - ~29.9 (version 3) fps). I blame test machine, partially (it’s dual core and as you can see at Figure 1, the test utilizes 2-3 cores most of the time). I may test it on my quad-core work machine and will get back with the results (if they’re interesting).
As a finishing touch I added specialized, cache-friendly allocator to avoid false sharing and experimented with different kinds of queues, like the one presented in Herlihy’s book (pretty nice BTW’ with dollar so dirt cheap I’m going crazy with Amazon, I think I’ve been spending ~100USD/month on books recently, waiting for one about TBB now). It falls down to slower interlocked operations only if needed. Haven’t noticed significant performance improvements to be honest, but it takes less memory in most cases (represented as array instead of linked list) and doesnt need node allocator.
Finally, just for kicks - my take on parallel_for:
struct ApplyFoo
{
explicit ApplyFoo(int* tab): m_tab(tab) {}
void operator()(const rde::pair<int, int>& range)
{
for (int i = range.first; i != range.second; ++i)
m_tab[i] = Foo(m_tab[i]);
}
int* m_tab;
};
[...]
ApplyFoo f(&tab;[0]);
ParallelFor(pool, 0, tabSize, f);Old comments
supzi 2008-06-13 12:50:27
Funny, synchronization can really lower performances depending on how you use it
I had the same fun some time ago, you can see that at http://supzi.wikidot.com/little-concurrency-fun-with-stl
therealremi 2008-06-13 18:14:11
Regarding the Herlihy book - I got it also but I’m a bit scared to read it cause people say lot’s of code samples have bugs. Did you notice any?
admin 2008-06-13 19:19:28
I’ve only skimmed it so far, but havent noticed bugs.