Going deeper
27/Apr 2014
Few weeks ago I encountered a discussion on a Polish gamedev forum – participants were wondering whether it’s faster to access stack or heap memory. I didn’t pay much attention (there should be no significant difference) until someone had posted a test case. Out of curiosity, I ran it and to my surprise discovered, it was consistently faster for buffers allocated on the stack. We’re not talking about few cycles here and there, too, the difference was almost 20% (Ivy Bridge laptop). Test itself is a little bit contrived, but turned out to be an interesting study. Code is exactly the same in both cases, we simply increment all elements of an array:
1for(int i = 0; i < iterations; i++)
2{
3 for(int j = 0; j < arraySize; j++)
4 {
5 stackArray[j]++;
6 }
7}
8[...]
9char stackArray[arraySize];
10char* heapArray = new char[arraySize];I refused to believe it was actually a memory access making a difference so decided it’s time to dig deeper. Let’s take a look at the very inner loop for these two cases, as it turns out it’s slightly different:
// Stack:
00D1100D BB 01 00 00 00 mov ebx,1
[...]
00F11014 00 98 40 30 F1 00 add byte ptr stackArray (0F13040h)[eax],bl
00F1101A 03 C3 add eax,ebx
00F1101C 3B 05 3C 21 F1 00 cmp eax,dword ptr [arraySize (0F1213Ch)]
// Heap:
00D11036 8B 0D 48 30 E1 00 mov ecx,dword ptr [heapArray (0E13048h)]
[...]
00D1103E FE 04 01 inc byte ptr [ecx+eax]
00D11041 40 inc eax
00D11042 3B 05 3C 21 D1 00 cmp eax,dword ptr [arraySize (0D1213Ch)]As you can see – it’s pretty close, main difference seems to be using INC instead of ADD. Back in the old days, comparing performance was easy, we’d just see how many cycles INC/ADD costed. Pentium complicated things a little bit with U/V pairing and with modern out-of-order processors it’s even more tricky. Without going in gory details, CPUs can split instructions into smaller, more RISCy operations named micro-ops. add [mem], reg is a good example, it’ll be split into 4 uops (load, add, calc write address, store). To make things more interesting, some of these micro-ops can be then fused again into a single operation (some of pipeline stages can only process a limited number of uops, so this reduces bottlenecks). Different CPUs have different fusion capabilities, but my Ivy Bridge should be able to fuse our 4 uops back to 2. Let’s verify our assumptions using Agner’s MSR driver (I mentioned it before). Results from test run for the “stack version”, array size = 1024, 1 iteration:
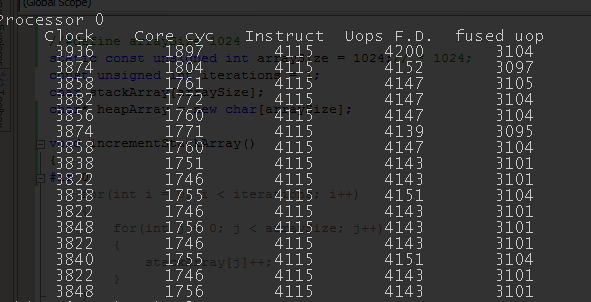
Uops F.D = uops fused domain, fused uops count as 1 Fused uops = # of fused uops
As we can see, inner loop costs 4 uops per iteration (after fusion). Let’s see the results for inc byte ptr [ecx+eax]:
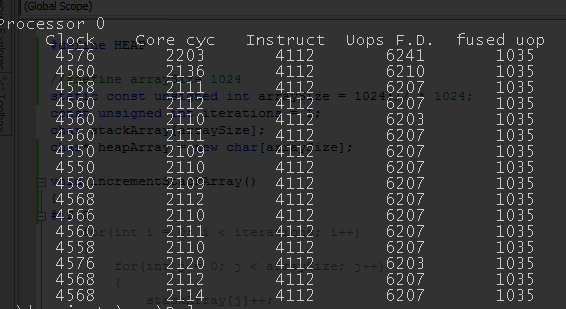
Ouch. As you can see, number of instructions is almost exactly the same, but we generate way more uops (6k vs 4k, 2 uops more per iteration) and micro-op fusion doesn’t seem to do a very good job. Where does the difference come from? As usually, in such case, I start with Agner Fog’s site. As it turns out, there’s some subtlety to memory store instructions - if they don’t use SIB byte, they only cost 1 uop, otherwise - it’s 2. If you look at our “heap code”, it’s clear we need a SIB byte (it’s necessary if there’s more than 1 pointer register), that means 2 uops. Let’s try to modify the assembly code so that we don’t use 2 registers:
mov eax, dword ptr heapArray
mov ecx, eax
add ecx, arraySize
l1:
inc byte ptr [eax]
inc eax
cmp eax, ecx
jb l1Results:
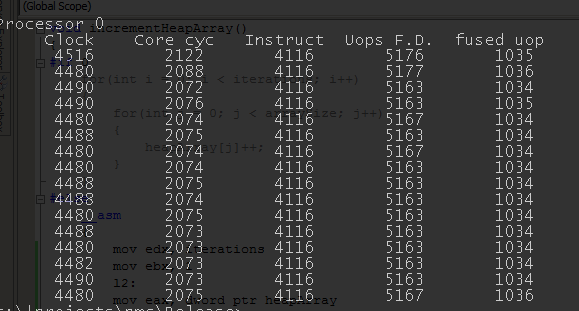
Progress! We eliminated 1 uop per iteration. Still not exactly on par with the first version, but we’re getting there. The remaining difference is INC vs ADD. I actually asked Agner Fog about it, he rightfully pointed out it’s probably related to the fact INC needs to preserve the carry flag (for legacy reasons). (Sidenote: every time I ask Agner about something, he replies almost immediately… After that I imagine the volume of mail he must be getting, compare to the time it takes me to answer an email and start feeling bad). It’s also clearly noted in his “Instruction tables” doc (INC = 3 uops fused domain, ADD = 2) and Intel discourage using INC in their docs as well. Let’s replace INC with ADD and see the results:
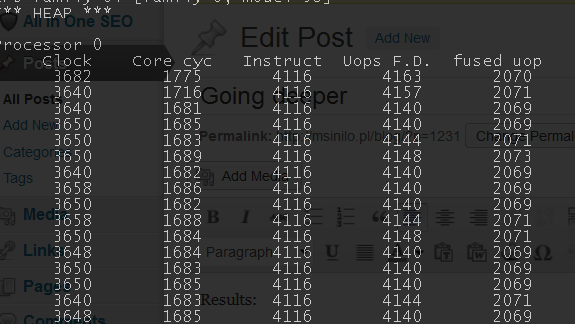
That’s more like it! As you can see, we now generate 4 uops per iteration (same as the first version). The only thing that was still bothering me as the difference in the fused uop number (~2k here, ~3k in the first one). I figured it had something to do with cmp instruction using register (vs memory in the first one). Using “Instructions table” again we can notice that CMP m, r/i is actually not fused, while CMP r, r/i is. I also discovered another tool that’s helpful in such situations - Intel Architecture Code Analyzer. Compare output for cmp reg, mem & cmp reg, reg:
| 2^ | 0.3 | | 0.5 0.5 | 0.5 0.5 | | | 0.8 | | | cmp eax, dword ptr [0x0]
| 1 | 0.3 | | | | | | 0.8 | | | cmp eax, 0x400
^ means that micro-op fusion happened here (2 uops fused into 1). IACA doesn’t seem 100% reliable (e.g. it doesn’t seem to catch the INC vs ADD difference), but it’s another helpful tool in our collection.
Obviously, going to the micro-op level is not something you’ll be doing often (or ever, to be honest), it only makes sense if you’re actually writing assembly, otherwise it’s in the hands of the compiler. I still think it’s fun and an interesting way to understand how the modern CPUs work under the hood.
Old comments
mr 2014-04-27 10:06:22
Nice research! So, if this test case goes to the right people, maybe clang and/or gcc will take such optimization into account, if they don’t already.
Mike G. 2014-04-27 14:22:51
Very interesting.
But, in the usual case where oddities about compiler instruction choices aren’t involved, wouldn’t you expect the stack variables to be much likelier to be in-cache, since stack frames re-use the same memory area quite a bit?
I suspect the performance difference is down to usually 0 trips to main memory to read the stack variable, and usually 1 to read the heap memory.
admin 2014-04-27 16:12:21
mr - admittedly, this is probably still mostly interesting as a learning experience. Problem is, the behavior varies between different CPUs, too. I did some limited tests on Haswell and it seems that even if it generates more uops (for v2), it just doesn’t care and performance is roughly the same.
Mike G. - you’re probably right, but it’s almost impossible to control and as you noticed - it probably comes down to just 1 “extra” miss. Also, in this particular case it wasn’t even function’s stack, just global array (BSS).
xoofx 2014-04-28 21:59:23
In the asm loop, it should be inc eax instead of inc ecx
admin 2014-04-29 02:32:44
Yup, that’s right, thanks for correction.
Emmanuel Astier 2014-05-01 15:24:08
Thanks for this low level article. It’s nice to still see people digging at this level !
Now my question is : why on earth did the compiler did that ?
It’s its responsability to know about this low level stuff, and produce the optimized code…