MESIng with cache
22/Dec 2014
(Please excuse the terrible pun, couldn’t help myself).
As we all know, computer cache is a touchy beast, seemingly little modifications to the code can result in major performance changes. I’ve been playing with performance monitoring counters recently (using Agner Fog’s library I mentioned before). I was mostly interested in testing how cmpxchg instruction behaves under the hood, but wanted to share some other tidbits as well.
Let’s assume we’re working with a simple spinlock code. There are a few ways of implementing one, each with slightly different characteristics. Let’s start with the most basic one:
1void Lock()
2{
3 while(_InterlockedExchange(&mLock, 1) == 1)
4 {
5 [..]// spin
6 }
7}Notes:
“spin” code could be a whole post in itself and it’ll affect the performance. As mentioned, I was mostly interested in mechanics of cmpxchg, so I went with simple exponential backoff (if I wanted to amplify the effects of chosen ‘lock’ mechanism I could have gone with just spinning on single ‘pause’ instruction, but that felt too contrived).
InterlockedExchange compiles to xchg reg,dword ptr [mem]
Not posting code to Unlock, it’s the same in all experiments and boils down to setting mLock to 0 (atomically)
Let’s now think what happens if we have a high contention scenario with many threads (more importantly – many cores) trying to access the same variable and obtain the same lock. I’ll assume you’re familiar with the MESI protocol, so I’ll spare you the details (if not, Wikipedia has a decent write-up actually). The important part here is that as long as cache line containing mLock is in Modified or Exclusive state, we can read from it/write to it without having to communicate with other caches (we’ll need to write it back to main mem if it changes obviously, but that’s another issue). Sadly, with many threads banging on it, it’s quite unlikely, as different caches keep “stealing” the ownership from each other. As mentioned, InterlockedExchange compiles to xchg reg, [mem]. You might be surprised there’s no “lock” prefix, but it doesn’t matter in this particular case – Intel processors will automatically lock the bus “when executing an XCHG instruction that references memory” (see Intel Architecture Software Developer’s Manual Vol 3 for details). Not only we lock the bus, we also issue the infamous RFO message (Read For Ownership) in most cases (when we don’t own the line exclusively). This will cause all other processors to drop this line (set it to Invalid), so next time they try to access it, they’ll miss. Modern CPUs try to be smart about it and hide some of the associated overhead with store buffers and invalidate queues, but it still hurts. Consider the following modification to our lock code:
while(mLock == 1 || _InterlockedExchange(&mLock, 1) == 1)Before analyzing this change, let’s run a quick benchmark - quad core CPU, 4 threads, all fighting to access the same variable and increase it (500000 times each).
- v1: ~64ms on average,
- v2: ~59ms on average,
Not huge, but significant difference and it actually increases with contention. That’s hardly surprising and actually well known, we’ve just implemented test-and-set (v1) and test and test-and-set locks (v2) [and if we want, we can complicate things further with tickets or array locks]. The idea here is we spin mostly on reading from local cache, so no need to communicate with other CPUs, we only do it when we think we have a chance of succeeding. Things get a little bit more interesting as the contention decreases. With 2 threads fighting for access, the results are as following:
- v1: ~19ms
- v2: ~23 ms
Uh, oh… The lesson here I guess is not to apply “one size fits all” solutions to everything. Lots of benchmarks out there tend to focus on super high contention scenarios. They are important sure, but sometimes they feel a little bit counter-intuitive as well. After all, if we have 4+ threads banging on the same lock, perhaps it’s a good idea to reduce the contention first? Treat the cause, not the symptom. It’s hard to come up with solutions that are clearly superior for all scenarios. There’s actually an interesting discussion at the Linux Kernel discussion list on this very subject (cmpxchg, not xchg, but similar principles apply, in the end they decided to reject TTAS). In case of ‘light’ contention, our xchg will succeed in majority of cases, so extra read actually hurts us more than it helps.
Let’s dig a little bit deeper now and run our test PMC snippets. I added a bunch of performance counters, mostly related to cache activity and ran the tests again. 4 threads (click to enlarge):
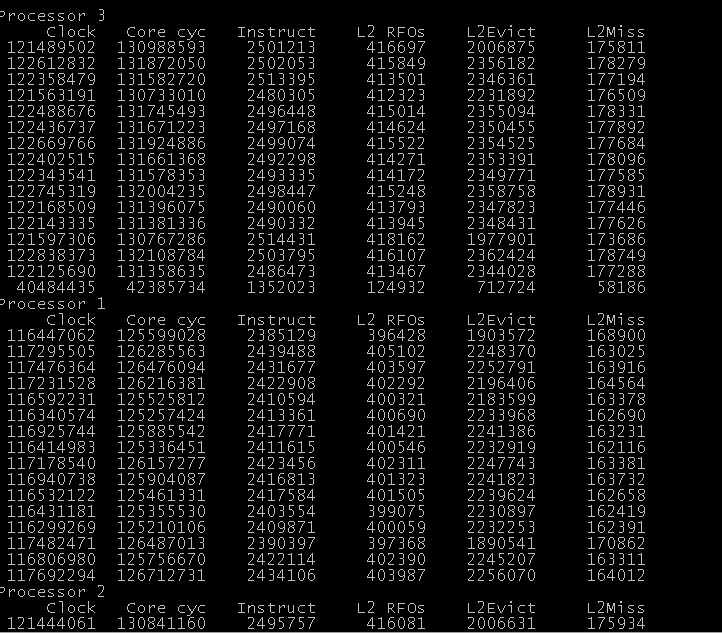

(Results for CPU 1 & 0 were very similar). As you can see there’s clearly more cache traffic in the TAS case, even though the instruction count is very similar. I added the following counters:
{161, S_ID3, INTEL_IVY, 0, 3, 0, 0x24, 0x0C, "L2 RFOs" },
{162, S_ID3, INTEL_IVY, 0, 3, 0, 0xF2, 0x0F, "L2Evict" },
{163, S_ID3, INTEL_IVY, 0, 3, 0, 0x27, 0x02, "RFO.S" },
{164, S_ID3, INTEL_IVY, 0, 3, 0, 0x26, 0x01, "L2Miss" },- L2 RFOs = number of store RFO requests (=L1D misses & prefetches),
- L2Evict = L2 lines evicted for any reason
- L2Miss = take a guess
Let’s try with 2 threads next:

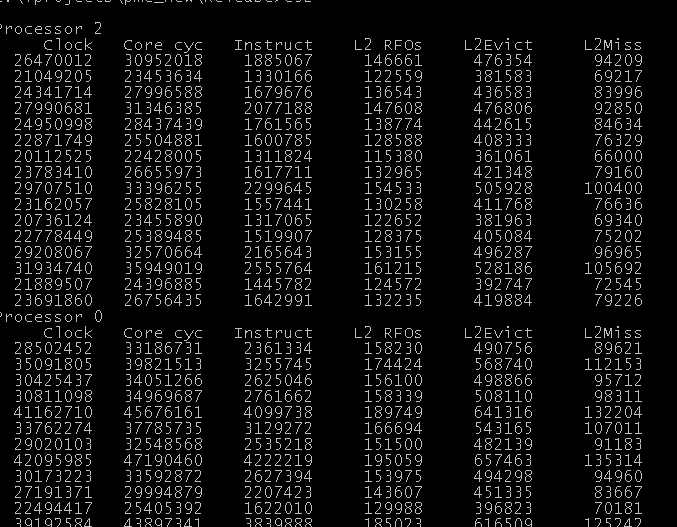
As you can see, there’s still less RFOs, but interestingly – the number of misses is almost the same and TTAS generates more instructions, obviously.
There’s one more way of implementing our spinlock and that’s a cmpxchg instruction:
while(_InterlockedCompareExchange(&mLock, 1, 0) == 1)How do you think, is it closer to TAS or TTAS? First thought could be TTAS, after all it’s a very similar idea, we compare against expected value first, then exchange. There are few differences, though. For one, _InterlockedCompareExchange compiles to lock cmpxchg, so we lock the bus before reading. Also, it’s 1 fairly complicated instruction, not 2 or more. According to Agner Fog’s tables, lock cmpxchg is 9 uops (as compared to 7 for xchg). There are some more interesting (and perhaps surprising) properties, but first some benchmarks (v3). 4 threads:

It seems like it’s very close to the xchg instruction. This is what you could expect based on this paper on scalable locks from Intel, but to be honest, I was a little bit surprised at first, especially by the fact it seems to generate similar cache traffic. As it turns out – cmpxchg instruction itself is actually quite close to xchg as well (they work differently, but trigger similar mechanisms):
cmpxchg implies an RFO, in all cases, even if comparison fails. Some confirmation here (LKML again) and it’s also what shows in PMC tests above,
another interesting question is – does lock cmpxchg always result in a write? Again, the answer seems to be “yes”. That’s based on Agner’s tables (1 p4 uop. p4 = memory write) and the fact that ops that lock the bus are expected to write to memory. There’s some more information here for example, if comparison fails, the destination operand is simply written back as if nothing happened.
The beauty of cmpxchg is that it does the comparison & swap atomically, so it’s perfect for more complicated scenarios (like MPMC containers, where we need to swap list head for example), but our case here is very simple, we just ping-pong between 0 & 1. When trying to obtain lock by using xchg, if it’s already taken, we’ll simply write 1 to it again, it doesn’t break anything, cmpxchg doesn’t really buy us much. I actually found a patent application for a FASTCMPXCHG instruction (from Intel engineers). The idea is that in some cases CPU replaces the whole load-compare-store chain with simple final store (AFAIK it’s not implemented in any hardware).
For some more benchmarks of various memory operations/different CPUs see also this Gist from Ryg.
Old comments
cb 2015-01-07 21:05:11
cmpxchg is declared to be a sequence point and counts as an RMW op for atomic ordering purposes even if it fails to exchange. This means it can’t internally be optimized like a TTAS.